Street Fighter 6 マスターランクランキング
データ取得と分析概要
BUCKLER マスターランクランキングから Python と Selenium を用いてデータを取得し、 キャラクターごとのプレイ傾向を分析するための仕組みと、その一例として リュウ vs サガットの比較結果を示します。
1. 目的と全体像
BUCKLER マスターランクランキングから、
- 順位
- プレイヤー名
- 使用キャラクター
- MR(Master Rating)
- ユーザーID(プロフィール URL から抽出)
を取得し、Python / pandas による分析のための CSV データを作成します。 そのうえで、キャラ別の MR 分布・プレイスタイル指標の分布を比較し、 「どのキャラがどのような傾向を持って戦われているのか」を定量的に見ることを狙いとしています。
実装のステップは次の 4 つです。
- ログインセッションから Cookie を保存
- ランキング総ページ数を取得し、MR 帯ごとにページ範囲を推定
- 全体 or キャラ別ランキングをページ数指定でスクレイピング
- 特定キャラ・特定ページ範囲の詳細取得(サガットなど)
※ 個人の学習・研究目的での利用を前提としています。
※ 公式サイトの利用規約やサーバー負荷には十分配慮し、アクセス頻度は控えめにしています。
2. ログインセッションの Cookie 保存
BUCKLER はログイン前提のページ構成のため、最初にブラウザで手動ログインし、 そのセッション情報(Cookie)を JSON で保存します。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import json
import time
# 1. 手動ログイン用のブラウザを起動
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),
options=options)
# 2. BUCKLER ランキングにアクセスして手動ログイン
driver.get("https://www.streetfighter.com/6/buckler/ja-jp/ranking/master")
print("🔑 ブラウザでログインしてください(30秒待機)")
time.sleep(30)
# 3. Cookie を保存
cookies = driver.get_cookies()
with open("cookies.json", "w", encoding="utf-8") as f:
json.dump(cookies, f, indent=2, ensure_ascii=False)
driver.quit()
一度 cookies.json を作っておけば、以降のスクレイピングでは Cookie を読み込むだけで
ログイン状態を再現できます(有効期限が切れたら再取得)。
3. ランキング総ページ数と MR 帯推定
3-1. 総ページ数の取得
まず、マスターランクランキング全体が何ページあるのかを取得します。
from selenium.webdriver.common.by import By
import re
import time
driver.get("https://www.streetfighter.com/6/buckler/ja-jp/ranking/master")
time.sleep(3)
try:
last_page_element = driver.find_element(By.CLASS_NAME,
"ranking_ranking_now__last__oqSXS")
last_page_text = last_page_element.text.strip()
match = re.search(r"\d+", last_page_text)
if match:
total_pages = int(match.group())
print(f"ランキングの総ページ数: {total_pages}")
else:
print("ページ番号の抽出に失敗しました")
except Exception as e:
print(f"最終ページ要素の取得に失敗: {e}")3-2. MR 帯ごとのページ範囲推定
事前に集計した MR 帯ごとの割合 に基づき、ランキング上で どのページがどの MR 帯に対応しているかを概算します。
mr_distribution = {
"~999": 0.1321,
"1000~1099": 0.1318,
"1100~1199": 0.1307,
"1200~1299": 0.1271,
"1300~1399": 0.1180,
"1400~1499": 0.1007,
"1501~1599": 0.0661, # MR1500 除外済み
"1600~1699": 0.0328,
"1700~1799": 0.0171,
"1800~1899": 0.0085,
"1900~1999": 0.0040,
"2000~2099": 0.0020,
"2100~2199": 0.0008,
"2200~2299": 0.0004,
"2300~2399": 0.00008,
"2400~2499": 0.00002,
}
estimated_ranges = {}
current_start = 1
for mr_range, ratio in sorted(mr_distribution.items(),
key=lambda x: -int(re.search(r'\d+', x[0]).group())):
pages = int(round(total_pages * ratio))
start_page = current_start
end_page = current_start + pages - 1
estimated_ranges[mr_range] = {
"ページ数": pages,
"開始ページ": start_page,
"終了ページ": end_page
}
current_start += pages
print("MR 帯ごとのページ範囲(例):")
for mr, info in estimated_ranges.items():
print(f"MR {mr}: {info['ページ数']} ページ({info['開始ページ']}〜{info['終了ページ']})")これにより、例えば「MR 2000〜2099 帯がランキングのどのあたりに分布しているか」をおおまかに把握し、 必要なページ帯だけを重点的に取得するといったことが可能になります。
4. ランキング取得(全体・キャラ別)
4-1. キャラクター指定ロジック
キャラ名から BUCKLER の character_id を引くマッピングを用意しています。
character_name = None # None の場合は全キャラ
character_id_map = {
"リュウ": "ryu",
"ケン": "ken",
"ルーク": "luke",
"春麗": "chunli",
"ジェイミー": "jamie",
"マノン": "manon",
"キンバリー": "kimberly",
"ジュリ": "juri",
"JP": "jp",
"マリーザ": "marisa",
"キャミィ": "cammy",
"ディージェイ": "deejay",
"ザンギエフ": "zangief",
"ガイル": "guile",
"ブランカ": "blanka",
"エドモンド本田": "ehonda",
"ダルシム": "dhalsim",
"リリー": "lily",
"ラシード": "rashid",
"A.K.I.": "aki",
"エド": "ed",
"豪鬼": "akuma",
"ベガ": "vega",
"舞": "mai",
"テリー": "terry",
"エレナ": "elena",
"サガット": "sagat"
}
character_id = character_id_map.get(character_name) if character_name else None4-2. Cookie 読み込みとランキング URL 生成
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),
options=options)
# 先にドメインにアクセスしてから Cookie を投入
driver.get("https://www.streetfighter.com/")
time.sleep(2)
with open("cookies.json", "r", encoding="utf-8") as f:
cookies = json.load(f)
for cookie in cookies:
if "sameSite" in cookie:
del cookie["sameSite"]
driver.add_cookie(cookie)
base_url = "https://www.streetfighter.com/6/buckler/ja-jp/ranking/master"
if character_id:
url = f"{base_url}?character_filter=4&character_id={character_id}&page=1&season_type=1"
else:
url = f"{base_url}?page=1&season_type=1"
driver.get(url)
time.sleep(5)4-3. 1ページごとのデータ抽出
names = driver.find_elements(By.CLASS_NAME, "ranking_name__El29_")
ratings = driver.find_elements(By.CLASS_NAME, "ranking_time__teMP4")
characters = driver.find_elements(By.CSS_SELECTOR, "div.ranking_character__WoGAX img[alt]")
profile_links = driver.find_elements(By.CSS_SELECTOR, 'a[href*="/profile/"]')
ids_only = [re.search(r'/profile/(\\d+)', link.get_attribute("href")).group(1)
for link in profile_links if re.search(r'/profile/(\\d+)', link.get_attribute("href"))]
ids_only = ids_only[3:] # 先頭の不要なリンクをスキップ
data = []
idx = 0
for i in range(len(names)):
try:
name = names[i].text.strip()
if name == "EROICA_2040c":
continue # 特定ユーザーを除外する例
rating_text = ratings[i].text
rank_match = re.search(r"(\\d+)位", rating_text)
mr_match = re.search(r"(\\d+)MR", rating_text)
character = characters[i].get_attribute("alt").strip()
user_id = ids_only[idx] if idx < len(ids_only) else None
idx += 1
data.append({
"順位": int(rank_match.group(1)) if rank_match else None,
"名前": name,
"キャラクター": character,
"MR": int(mr_match.group(1)) if mr_match else None,
"ユーザーID": user_id
})
except Exception as e:
print(f"データ処理エラー(index={i}): {e}")
continue
最後に pandas.DataFrame に変換し、キャラ別でファイル名を変えつつ CSV に保存します。
5. サガットのページ範囲スクレイピング
より細かい分析のために、例えば「サガットの 1〜15 ページだけ」といった形で キャラとページ範囲を指定して取得するスクリプトも用意しています。 ここではページ番号も一緒に記録し、「どの順位帯のサガットなのか」を後から追えるようにしています。
character_name = 'サガット'
character_id = character_id_map.get(character_name)
start_page = 1
end_page = 15 # 0 を指定すると最終ページまで
# page=1 にアクセスした後、「次へ」ボタンで start_page までスキップ
def click_next():
try:
next_btn = WebDriverWait(driver, 8).until(
EC.element_to_be_clickable((By.CLASS_NAME, "ranking_next05__bNXbW"))
)
driver.execute_script("arguments[0].scrollIntoView(true);", next_btn)
time.sleep(0.4)
next_btn.click()
time.sleep(2)
return True
except Exception as e:
print(f"次ページボタン失敗: {e}")
return False
for _ in range(start_page - 1):
if not click_next():
break
# ページごとにスクレイピング(ページ番号も一緒に保存)
data = []
current_page = start_page
def scrape_current_page(page_no: int):
WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, "ranking_name__El29_"))
)
# ここで 4-3 と同様に names / ratings / characters / ids_only を作り、
# それぞれの行に "ページ": page_no を付けて data.append(...)
while True:
if not scrape_current_page(current_page):
break
if end_page != 0 and current_page >= end_page:
break
if not click_next():
break
current_page += 1
df = pd.DataFrame(data)
filename = "sf6_ranking_scraped_sagat_p1-15.csv"
df.to_csv(filename, index=False, encoding="utf-8-sig")6. 取得データの形式
最終的な CSV は次のような列構成になります。
順位名前キャラクターMRユーザーIDページ(ページ範囲版のみ)
これをもとに、キャラ別 MR 分布や、各種指標(コーナーにいる時間・パリィからのドライブラッシュ率など)を pandas で結合し、ヒストグラム・箱ひげ図などで可視化していきます。
7. 分析例:リュウ vs サガットの比較
ここでは、実際にスクレイピングしたデータと対戦ログを組み合わせて作成した ヒストグラムの例を示します。 青色の分布が リュウ、オレンジ色の分布が サガット を表しています。
7-1. corner_time(画面端にいる時間)
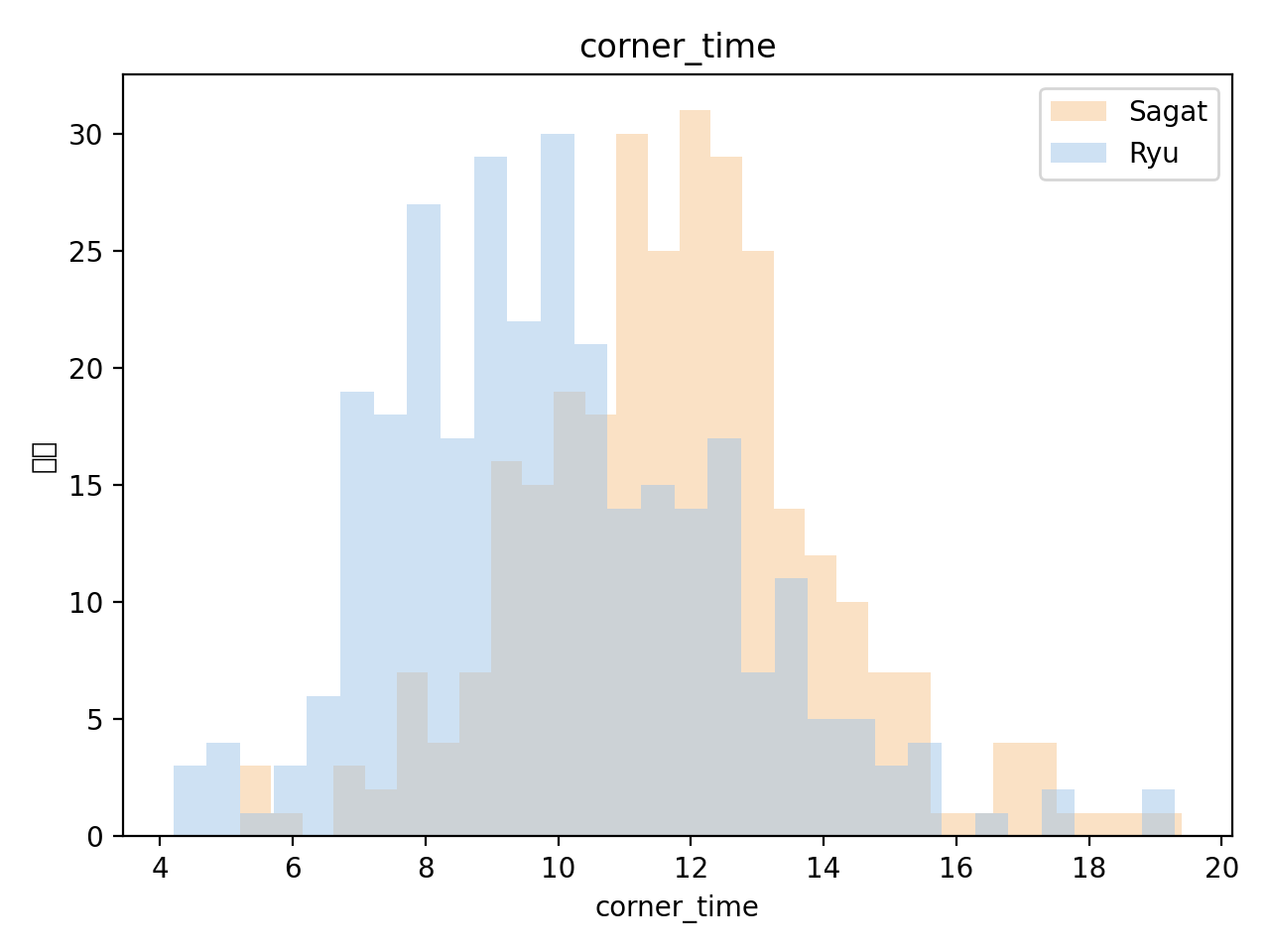
サガット(オレンジ)の分布は、リュウ(青)に比べて 全体的に右側にシフトしています。 これは、サガット側の試合では 「相手を画面端に押し込んでいる時間が相対的に長い」 傾向があることを意味します。
一方で、リュウは分布の裾が広く、端に詰める展開だけでなく、 画面中央〜中距離戦を行っている試合も多いと解釈できます。 「火力が高くリーチの長いサガット」と 「前ステ・差し返しも含めた万能型のリュウ」という キャラコンセプトの違いが、そのまま統計に出ている形です。
7-2. gauge_rate_drive_rush_from_parry(パリィからのドライブラッシュ率)
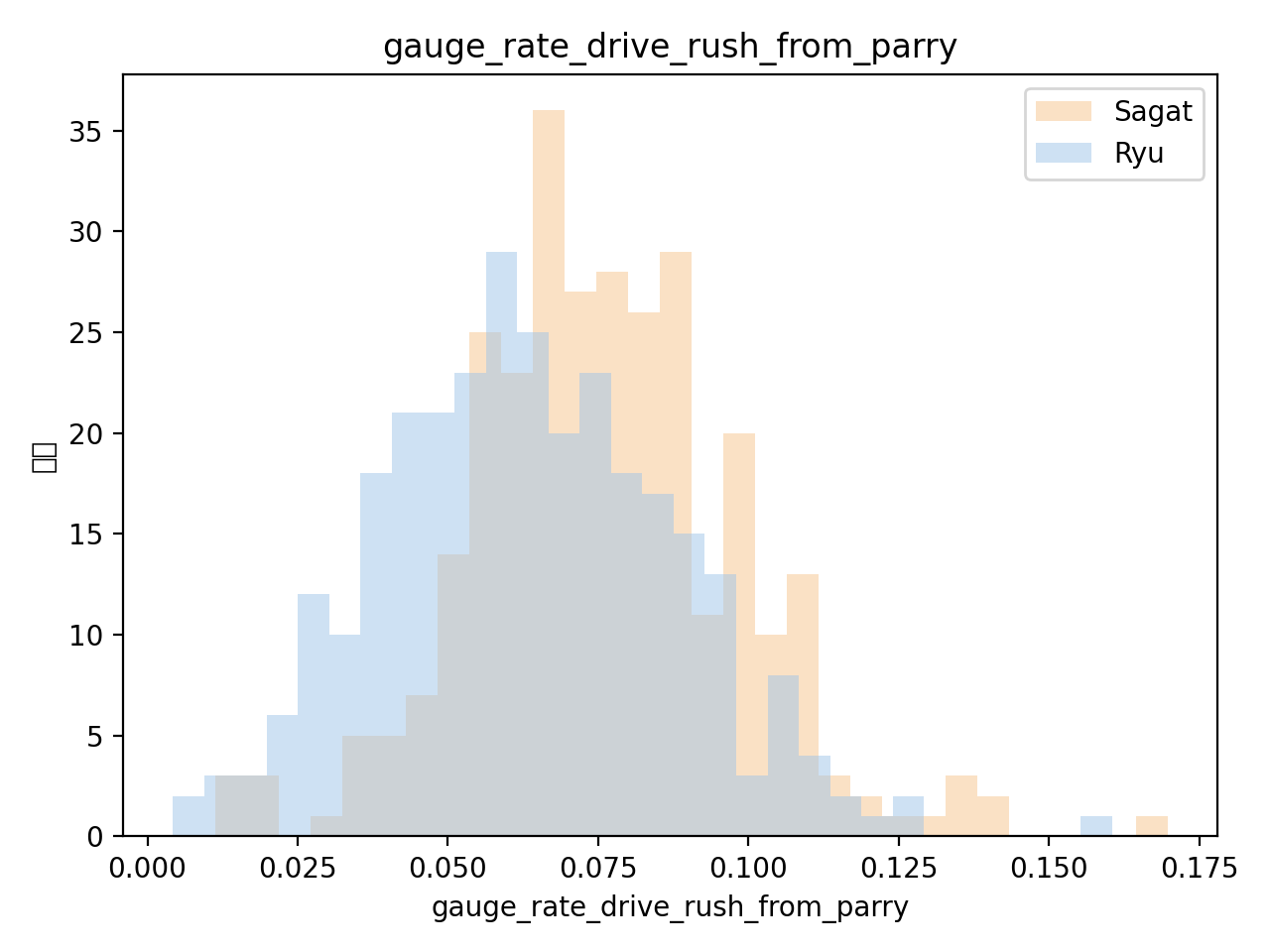
パリィ成功後にドライブラッシュで前に出ている比率を見たものがこの指標です。 サガット(オレンジ)の方が、分布がやや右寄りになっており、 パリィから積極的にラインを上げている プレイヤーが多いことが分かります。
逆にリュウ(青)は、やや低めの値に山があり、 パリィ後にその場で様子見したり、中距離の牽制に戻ったりする より「落ち着いた」選択が多いことが示唆されます。 いわばリュウは「オーソドックスで安定志向」、 サガットは「リスクを取ってでも前に出る砲台」といった プレイスタイルの違いが、行動ログの分布として可視化されています。
8. 今後の展望
今回はヒストグラムを用いて、単変量ごとに リュウとサガットの分布の違いをざっくり比較しました。 今後は、次のような方向で分析の高度化を予定しています。
-
多変量解析:
corner_time・パリィ関連指標・ジャンプ頻度・技振り回数などをまとめて扱い、 主成分分析(PCA)やクラスター分析で 「同じキャラでもプレイスタイルごとにグループ分け」する。 -
MR を説明するモデル構築:
各種行動指標を説明変数とし、MR や勝率を目的変数にした 回帰モデル/ロジスティック回帰を構築。 「どの行動が MR に一番効いているのか」を定量的に評価する。 -
シーズンごとのメタ変化の追跡:
シーズンごとに同じ指標を計測し、 バージョンアップや調整を挟んだタイミングで 分布がどのようにズレたかを時系列で可視化する。 -
キャラ間の相対比較ダッシュボード:
取得した CSV をもとに、Web 上でキャラを選ぶと ヒストグラムや箱ひげ図が切り替わるインタラクティブなダッシュボード (Plotly Dash / Streamlit 等)として公開することも視野に入れています。
このページは「データをどう集めて、どう読み解き始めているか」の技術メモにあたります。 実際の対戦への示唆や「じゃあどう立ち回りを変えるか」といった話は、 メインの「Street Fighter 6 のデータ分析」ページで順次まとめていく予定です。